
Potential and pitfalls of web-scale information acquisition for the biomedical domain
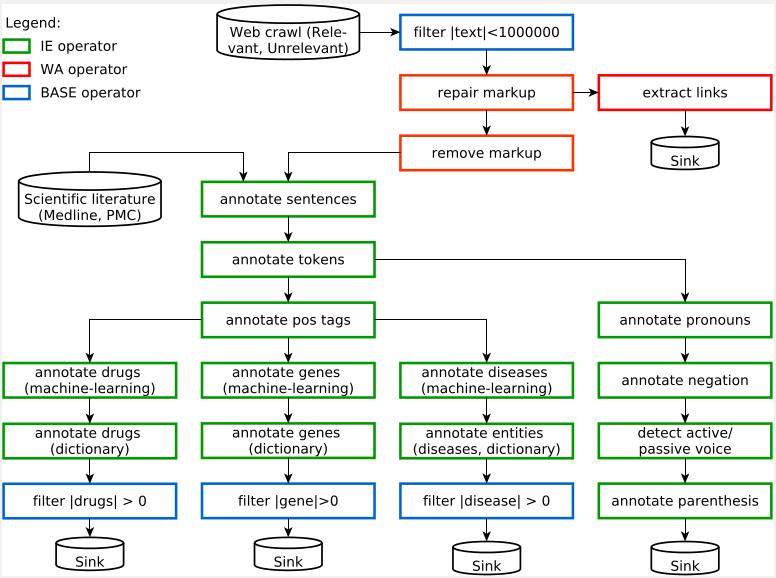
In many domains, a plethora of textual information is available on the web as news reports, blog posts, community portals, etc. Information extraction (IE) is the default technique to turn unstructured text into structured fact databases, but systematically applying IE techniques to web input requires highly complex systems, starting from focused crawlers over quality assurance methods to cope with the HTML input to long pipelines of natural language processing and IE algorithms. Although a number of tools for each of these steps exists, their seamless, flexible, and scalable combination into a web scale end-to-end text analytics system still is a true challenge. In this project, we built such a system for comparing the "web view" on health related topics with that derived from a controlled scientific corpus, i.e., Medline. The system combines a focused crawler, applying shallow text analysis and classification to maintain focus, with a sophisticated text analytic engine inside the Big Data processing system Stratosphere. Pages from a corpus of 1 TB highly enriched web pages for the biomedical domain were run through a complex pipeline of best-of-breed tools for a multitude of necessary tasks, such as HTML repair, boilerplate detection, sentence detection, linguistic annotation, parsing, and eventually named entity recognition for several types of entities. Results are compared with those from running the same pipeline (without the web-related tasks) on a corpus of 24 million scientific abstracts and a third corpus made of 250K scientific full texts. We evaluate scalability, quality, and robustness of the employed methods and tools. Our analysis suggests that a comprehensive analysis of web pages has the potential to augment knowledge contained in biomedical databases and peer-reviewed publications. Yet, we identify several open research and engineering challenges for the database community that need to be resolved until web-scale information extraction for the biomedical domain becomes an almost effortless task.
High-level analysis data flow implemented in Stratosphere:
Publication
- Rheinländer, A., Lehmann, M., Kunkel, A., Meier, J., Leser, U.: Potential and Pitfalls of Domain-Specific Information Extraction at Web Scale. SIGMOD, 2016.